
“爆款”的出现不是偶然现象,更不靠的是运气。
但很多服装企业却每年都“押”爆款,有的能够“押中”款式,把它销售成为“爆款”;
但有的却从来都拿不准,跟着人家拿“爆款”,最终只见库存不见钱。
那么“爆款”是怎么来的呢?如何能够客观和冷静地计划出爆款?

“爆款”背后也是有套路的
简单来说,“爆款”的数量并不多,大多数都是相对基础的款式。
要跑赢时间达到当季销量的最高点,“爆款”必须符合当下的流行色和流行款,款式好穿搭且不挑人。
对消费者而言,无非是懒得研究,没有很强的自我主见,干脆人云亦云,同时又囊中羞涩,“爆款”便宜又好看,那就也来一件。
“爆款”的销售是有周期性的,卖的人多竞争越来越大,购买人群却不断减少,进而导致“烂大街”的款式渐渐也就卖不动了。
所以想做出“爆款”,设计师们还是要走在前列,早早地发掘出能够爆销的款式。
在调研了很多服装店的畅销“爆款”后,我们发现其实“爆款”特征十分明显。
①质量、版型、细节都要好
产品本身一定是营销的前提,穿起来舒服是让消费者感觉质量好最重要的部分,像拉链容易坏、领子扎人、羽绒跑毛这样的质量问题,毫无疑问与爆款绝缘。
宽松型是适合大多数人的版型,也是这几年最受欢迎的版型。它不强调曲线、也不要求身材,传达出一种随性穿衣的态度。
并不是说“爆款”就一定是这个型,市场定位不同适合的版型也不同,唯一的准则是包容度。
②款式简练
总的来说,衣服简洁又百搭,颜色不挑肤色,不挑体型不挑人的服装往往才能销得多,卖得好。
绝大部分消费者喜欢整体简洁,但同时细微之处又能显示设计感的服饰来凸显自己的与众不同。
太花俏的,太夸张的款式是在挑选消费者。
③ 颜色合适
颜色的选择依据来自于我们的心理和肤色。
以集体主义为代表的中国人大部分对于色彩的选择还处在相对保守的状态,中国人更喜欢有彩色的部分出现在局部位置,而非全身。
而且对于偏黄的肤色,颜色太艳的服装就不衬肤色,脸部会显得暗淡甚至显黑。
④ 容易百搭
想要成为“爆款”,一定不能少的特征就是百搭。一件百搭的服装,不管是会穿搭的还是不会穿搭的人都会喜欢。
一件衣服能否在市场上发挥出他最大化的竞争优势,绝大原因取决于它的互搭性,包括款与款之间,主题与主题之间,色与色之间的搭配。
⑤ 价格适中
对大多数消费者而言,价格因素很难不被考虑。太贵,消费者咬牙切齿难下决心,太便宜,又觉得像个购物陷阱,还是走为上。
所以“爆款”不是最贵或者最便宜的,而是在整个店里的货品中,价格相对适中的。
⑥ 相对唯一
在爆款真正出现之前,同时出现很多类似款,这些款大同小异,本无可厚非,但如果集中到了一个店中,就容易在自家“火拼”,这就很难产生爆款。
⑦ 上市时间和销售周期
如果错过最佳的销售时间,再好的衣服也只能被处理。一个款式的销售周期长意味着能卖的时间长,那就容易跑量,服装人有时是靠天气吃饭的。
⑧ 库存
最悲催的情况恐怕是当消费者想买,却缺货了。库存在这个时候就不是库存了,只要拥有足量的库存才能满足爆款的销售,因此首单足,翻单快,易补货也是爆款的一个特征。通过“定性”分析,我们总结出了“爆款”服装以上几个特征,但看过后感觉这些似乎大家也都知道,看懂了产品的价值并不代表就能够制造它。
那我们把上面的分析再进一步分析,到达属性标签层级。
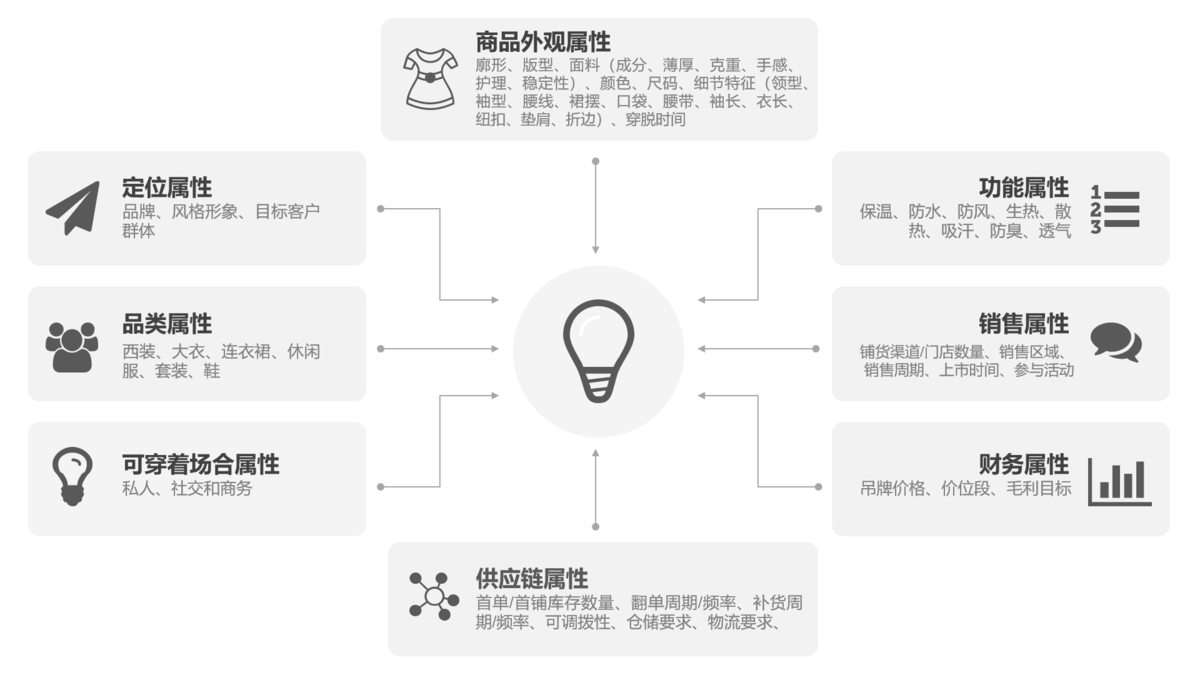
到此,还是让人感觉真理只掌握在了少数人手中,这些属性特征其实大家也都知道,虽然有数据,但大家还是觉得“定性”,只可意会不可言传。
这些属性特征到底给“爆款”贡献的多少“料”,而且是能够衡量出来的,那才是真正的定量。
通过机器学习算法打造“爆款”预测器
我们可以采用机器学习的方法来预测“爆款”,可以从已有数据中学习出对于“爆款”有贡献的特征。
运用传统的逻辑回归,提升树模型,或深度神经网络用于“爆款”预测模型。

首先,我们可以通过机器学习结合人工经验去选择出一些特征,也可以去除掉一些和“爆款”无关的特征。
然后进行模型训练来得到“爆款预测”的机器学习模型。
当这个商品开始售卖之后,还可以加入一点和当前销售表现相关的特征,来提升模型的精确度,一旦发现“爆款”的概率很高,可以快速决定追单。
Logistic Regression是比较经典的分类预测模型,具备很高的可解释性,我们可以对于类别变量做One-hot编码之后作为模型输入,每一个特征通过模型学习出来的系数,可以很清晰表达出此特征值对于“爆款”的影响。
当然,Logistic Regression是一个广义线性模型,对特征的表达比较简单。需要在特征工程这一步做较多的工作,生成部分的特征组合或者对特征先做一些聚类处理。
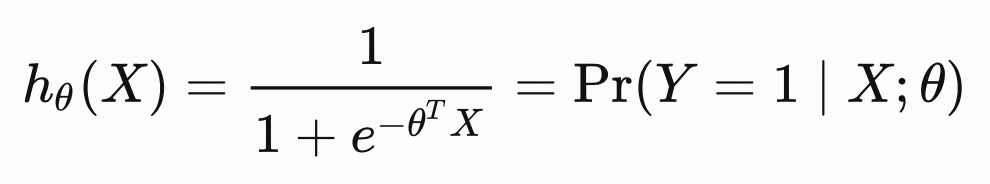
相对于Logistic Regression,树模型可以更好地学习特征中的非线性关系,同时树模型的可解释性也不错。
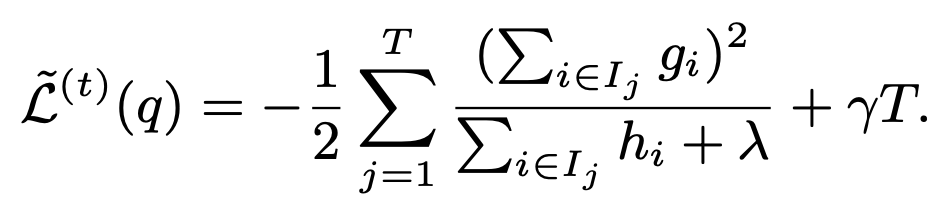
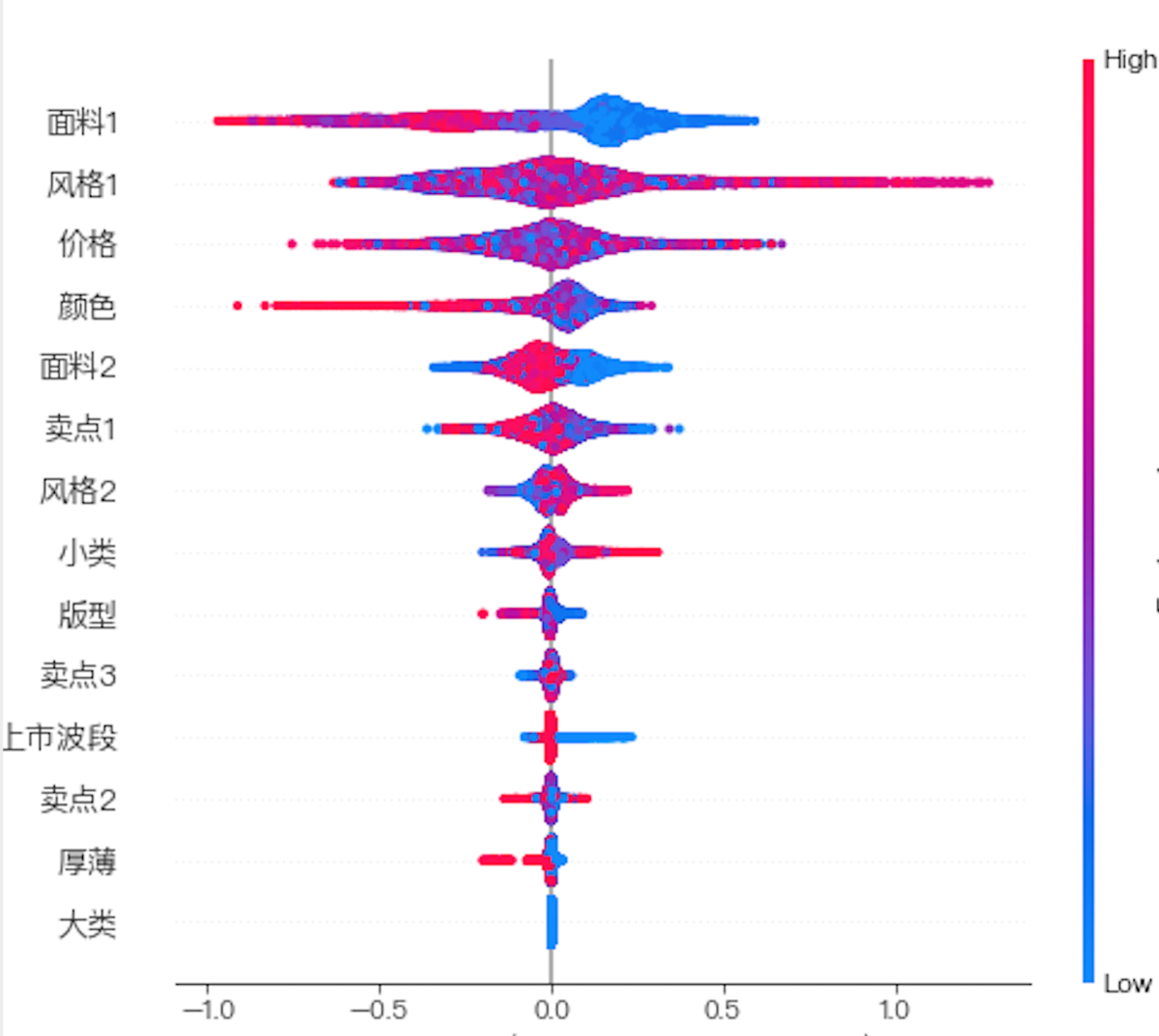
以下是一个树模型特征重要度的排序例子, 可以发现排在上面从中可以看到“面料1”、“风格1”、“价格”这些属性特征对于商品是否能成为“爆款”有比较大的贡献。
如果再进一步去剖析模型的树结构就可以看到这些属性特征在具体哪些值下面会对“爆款”有正贡献,哪些会有负贡献。
当然,除了树模型,最近比较火的深度神经网络同样可以用于爆款预测,特别当我们的特征是像商品的图片或者文字描述评价之类,这方面深度学习能够处理得比较好,只是在可解释性上没有树模型以及Logistic Regression来得那么容易表示。
所以,在有了模型之后,我们一方面可以对任意属性值的特征组合得到的商品去预测它成为“爆款”的概率。
另一方面,我们也可以从学习到的模型中去发现,哪些属性值的特征组合会高概率成为“爆款”,以及哪些组合很低概率成为“爆款”,给设计师提供很重要的参考。
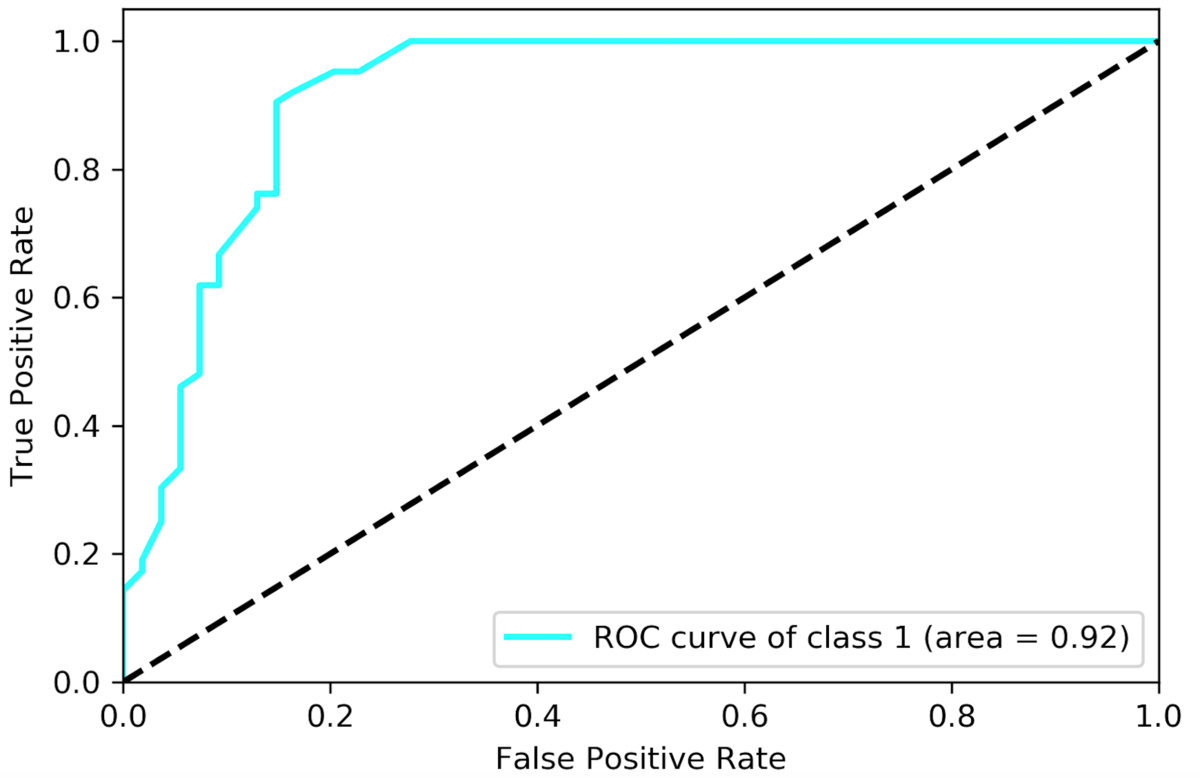
在预测结果的准确性上,通过模型计算出的“爆款”的准确率是可以科学地计算的,这根蓝色就是模型精度的一种表达,蓝色围出来的面积越接近1,准确率越高。
对于二分类模型,也就是预测某样东西是不是哪一类,一般都是用AUC这个指标。这里的AUC=0.92,这个的意思不是92%的准确率,但是是越接近1越高。
- 服装企业每年都会“押”爆款,但光从“爆款”的特征上去押,未免太碰运气。
- 如果你想通过科学的手段持续不断打造“爆款”,了解一下欧睿数据鞋服爆款打造器。
更多信息长按关注oIBP欧睿数据

往期精彩